開創性突破
在開源語言模型的演進過程中,DeepSeek R1的發布標誌著一個重要的里程碑。這個模型不僅展現出卓越的性能,更代表著開源AI領域的重大進展。透過最新的基準測試數據,我們得以一窺其非凡能力。
性能評測
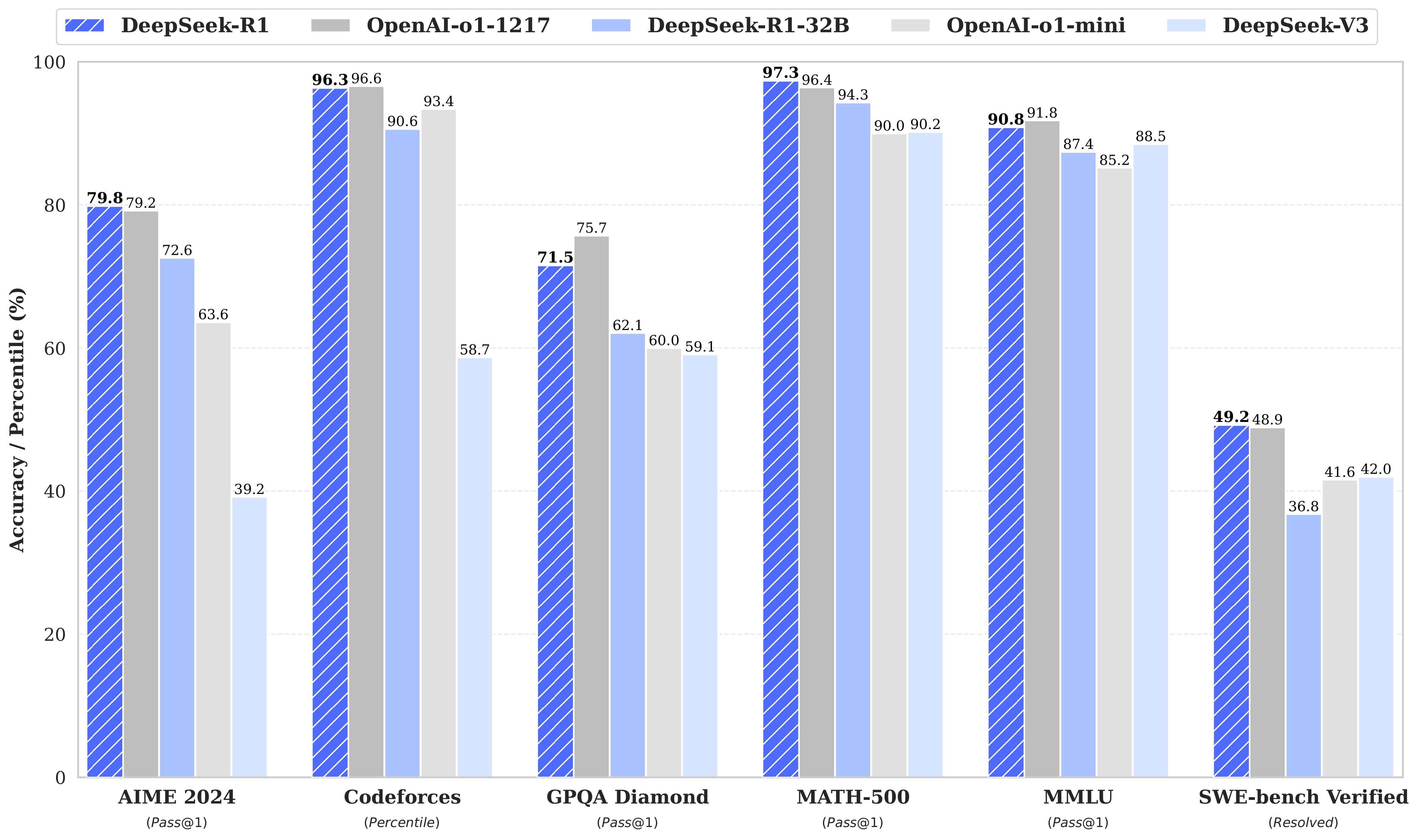
如上圖所示,DeepSeek R1在關鍵基準測試中展現出優異的表現。圖表清晰地呈現了DeepSeek R1(藍色條)與其他模型的比較,包括OpenAI-o1-1217(灰色條)和DeepSeek-R1-32B(淺藍色條)。
最新的測試結果令人振奮。在AIME 2024測試中,DeepSeek R1達到79.8%的準確率,超越了OpenAI-o1-1217的79.2%。在Codeforces程式設計測試中,取得了96.3%的驚人成績,幾乎與OpenAI-o1-1217的96.6%持平。特別值得注意的是其在MATH-500測試中的表現,DeepSeek R1以97.3%的成績超越了OpenAI-o1-1217的96.4%,展現出卓越的數學能力。
如圖表所示,在MMLU通用知識評估中,模型獲得了90.8%的強勁分數,與OpenAI-o1-1217的91.8%相當接近。即使在具有挑戰性的GPQA Diamond測試中,儘管以71.5%略低於對手的75.7%,仍然展現出強大的競爭力。這些指標清楚地表明,DeepSeek R1在多個關鍵領域已經達到或超越了商業閉源模型的水平。
技術創新
DeepSeek R1的成功源於其創新的技術架構。在注意力機制方面,團隊實現了新的優化設計,大幅提升了模型處理長文本的能力。改進的位置編碼技術使其能更好地理解文本關係。這些創新不僅提升了性能,還實現了計算資源的高效利用。
作為系列中的特別版本,DeepSeek R1 Zero在零樣本學習方面取得了革命性的進展。無需特定任務訓練,就展現出優秀的泛化能力。這種能力使其能靈活適應各種新場景,展現出顯著的適應性。
實際應用
在實際應用中,DeepSeek R1展現出多方面的才能。在軟體開發方面,它提供智能的程式碼補全建議,協助開發者重構程式碼,甚至生成自動化測試案例。在數學和科學計算領域,模型能解決複雜的數學問題,為研究工作提供強大支援。作為通用AI助手,它在對話互動、文檔生成和知識問答任務中表現出色。
開源價值
DeepSeek R1的開源發布對AI社群具有深遠影響。它不僅推進了開源AI技術,還降低了AI應用開發的門檻。通過開源程式碼,促進技術創新和知識共享,為整個AI生態系統注入新的活力。
未來展望
展望未來,DeepSeek R1的成功預示著開源AI模型的光明前景。隨著技術持續進步,我們期待看到性能的持續提升、應用場景的進一步擴展,以及社群生態系統的蓬勃發展。這些進展將為AI技術的民主化和普及化鋪平道路。
結論
DeepSeek R1的發布標誌著開源AI模型進入新的發展階段。它不僅展示了開源模型的巨大潛力,更為整個AI領域帶來新的可能性。通過持續的技術創新和社群協作,我們有充分理由期待更多令人興奮的進展。
親身體驗DeepSeek R1的深度思考能力 - 立即訪問DeepSeek R1 Chat!